Raster Vision is an open source framework for Python developers building computer vision models on satellite, aerial, and other large imagery sets (including oblique drone imagery). There is built-in support for chip classification, object detection, and semantic segmentation using PyTorch.

Raster Vision allows engineers to quickly and repeatably configure pipelines that go through core components of a machine learning workflow: analyzing training data, creating training chips, training models, creating predictions, evaluating models, and bundling the model files and configuration for easy deployment.
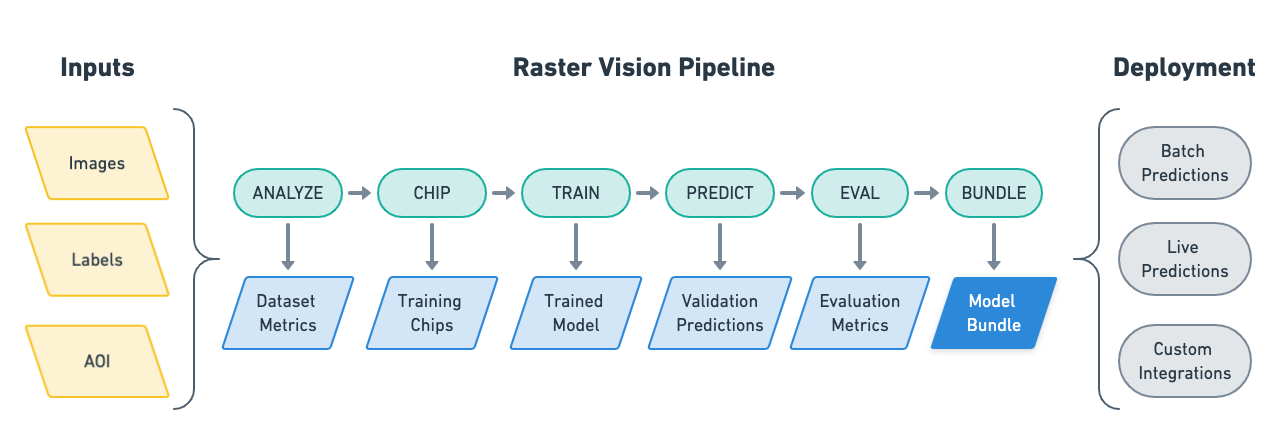
The input to a Raster Vision pipeline is a set of images and training data, optionally with Areas of Interest (AOIs) that describe where the images are labeled. The output of a Raster Vision pipeline is a model bundle that allows you to easily utilize models in various deployment scenarios.
The pipelines include running the following commands:
ANALYZE: Gather dataset-level statistics and metrics for use in downstream processes.
CHIP: Create training chips from a variety of image and label sources.
TRAIN: Train a model using a “backend” such as PyTorch.
PREDICT: Make predictions using trained models on validation and test data.
EVAL: Derive evaluation metrics such as F1 score, precision and recall against the model’s predictions on validation datasets.
BUNDLE: Bundle the trained model and associated configuration into a model bundle, which can be deployed in batch processes, live servers, and other workflows.
Pipelines are configured using a compositional, programmatic approach that makes configuration easy to read, reuse, and maintain. Below, we show the tiny_spacenet example.
# flake8: noqa
from rastervision.core.rv_pipeline import *
from rastervision.core.backend import *
from rastervision.core.data import *
from rastervision.pytorch_backend import *
from rastervision.pytorch_learner import *
def get_config(runner) -> SemanticSegmentationConfig:
root_uri = '/opt/data/output/'
base_uri = ('https://s3.amazonaws.com/azavea-research-public-data/'
'raster-vision/examples/spacenet')
train_image_uri = f'{base_uri}/RGB-PanSharpen_AOI_2_Vegas_img205.tif'
train_label_uri = f'{base_uri}/buildings_AOI_2_Vegas_img205.geojson'
val_image_uri = f'{base_uri}/RGB-PanSharpen_AOI_2_Vegas_img25.tif'
val_label_uri = f'{base_uri}/buildings_AOI_2_Vegas_img25.geojson'
channel_order = [0, 1, 2]
class_config = ClassConfig(
names=['building', 'background'], colors=['red', 'black'])
def make_scene(scene_id: str, image_uri: str,
label_uri: str) -> SceneConfig:
"""
- The GeoJSON does not have a class_id property for each geom,
so it is inferred as 0 (ie. building) because the default_class_id
is set to 0.
- The labels are in the form of GeoJSON which needs to be rasterized
to use as label for semantic segmentation, so we use a RasterizedSource.
- The rasterizer set the background (as opposed to foreground) pixels
to 1 because background_class_id is set to 1.
"""
raster_source = RasterioSourceConfig(
uris=[image_uri], channel_order=channel_order)
vector_source = GeoJSONVectorSourceConfig(
uri=label_uri, default_class_id=0, ignore_crs_field=True)
label_source = SemanticSegmentationLabelSourceConfig(
raster_source=RasterizedSourceConfig(
vector_source=vector_source,
rasterizer_config=RasterizerConfig(background_class_id=1)))
return SceneConfig(
id=scene_id,
raster_source=raster_source,
label_source=label_source)
scene_dataset = DatasetConfig(
class_config=class_config,
train_scenes=[
make_scene('scene_205', train_image_uri, train_label_uri)
],
validation_scenes=[
make_scene('scene_25', val_image_uri, val_label_uri)
])
# Use the PyTorch backend for the SemanticSegmentation pipeline.
chip_sz = 300
backend = PyTorchSemanticSegmentationConfig(
data=SemanticSegmentationGeoDataConfig(
scene_dataset=scene_dataset,
window_opts=GeoDataWindowConfig(
method=GeoDataWindowMethod.random,
size=chip_sz,
size_lims=(chip_sz, chip_sz + 1),
max_windows=10)),
model=SemanticSegmentationModelConfig(backbone=Backbone.resnet50),
solver=SolverConfig(lr=1e-4, num_epochs=1, batch_sz=2))
return SemanticSegmentationConfig(
root_uri=root_uri,
dataset=scene_dataset,
backend=backend,
train_chip_sz=chip_sz,
predict_chip_sz=chip_sz)
Raster Vision uses a unittest-like method for executing pipelines. For instance, if the
above was defined in tiny_spacenet.py, with the proper setup you could run the experiment
on AWS Batch by running:
> rastervision run batch tiny_spacenet.py
See the Quickstart for a more complete description of using this example.
Documentation¶
This part of the documentation guides you through all of the library’s usage patterns.
Configuration API¶
- Configuration API Reference
- rastervision.pipeline
- rastervision.core
- StatsAnalyzerConfig
- ClassConfig
- DatasetConfig
- SceneConfig
- ChipClassificationLabelSourceConfig
- SemanticSegmentationLabelSourceConfig
- ObjectDetectionLabelSourceConfig
- ChipClassificationGeoJSONStoreConfig
- PolygonVectorOutputConfig
- BuildingVectorOutputConfig
- SemanticSegmentationLabelStoreConfig
- ObjectDetectionGeoJSONStoreConfig
- RasterioSourceConfig
- RasterizerConfig
- RasterizedSourceConfig
- MultiRasterSourceConfig
- StatsTransformerConfig
- CastTransformerConfig
- NanTransformerConfig
- ReclassTransformer
- VectorSourceConfig
- GeoJSONVectorSourceConfig
- ChipClassificationEvaluatorConfig
- SemanticSegmentationEvaluatorConfig
- ObjectDetectionEvaluatorConfig
- ChipClassificationConfig
- SemanticSegmentationWindowMethod
- SemanticSegmentationChipOptions
- SemanticSegmentationConfig
- ObjectDetectionWindowMethod
- ObjectDetectionChipOptions
- ObjectDetectionPredictOptions
- ObjectDetectionConfig
- rastervision.pytorch_backend
- rastervision.pytorch_learner
- Backbone
- SolverConfig
- ExternalModuleConfig
- DataConfig
- ImageDataConfig
- GeoDataConfig
- GeoDataWindowConfig
- PlotOptions
- ModelConfig
- ClassificationDataFormat
- ClassificationDataConfig
- ClassificationImageDataConfig
- ClassificationGeoDataConfig
- ClassificationModelConfig
- ClassificationLearnerConfig
- SemanticSegmentationDataFormat
- SemanticSegmentationDataConfig
- SemanticSegmentationImageDataConfig
- SemanticSegmentationGeoDataConfig
- SemanticSegmentationModelConfig
- SemanticSegmentationLearnerConfig
- ObjectDetectionDataFormat
- ObjectDetectionDataConfig
- ObjectDetectionImageDataConfig
- ObjectDetectionGeoDataConfig
- ObjectDetectionGeoDataWindowConfig
- ObjectDetectionModelConfig
- ObjectDetectionLearnerConfig