Experiment Configuration¶
Experiments are configured programmatically using a compositional API based on the Fluent Builder Pattern.
Experiment Set¶
An experiment set is a set of related experiments and can be created by subclassing ExperimentSet. For each experiment, the class should have a method prefixed with exp_ that returns either a single ExperimentConfig, or
a list of ExperimentConfig objects.
In the tiny_spacenet.py example from the Quickstart, the TinySpacenetExperimentSet is the ExperimentSet that Raster Vision finds when executing rastervision run -p tiny_spacenet.py.
import rastervision as rv
class TinySpacenetExperimentSet(rv.ExperimentSet):
def exp_main(self):
# Here we return an experiment or list of experiments
pass
# We could also add other experiment methods
def exp_other_examples(self):
pass
if __name__ == '__main__':
rv.main()
ExperimentConfig¶
An experiment is a sequence of commands that represents a machine learning workflow.
The way those workflows are configured is by constructing an ExperimentConfig.
An ExperimentConfig is what is returned from the experiment methods of an ExperimentSet,
and are used by Raster Vision to determine what and how Commands will be run. While the
actual execution of the commands, be it locally or on AWS Batch, are determined by ExperimentRunners,
all the details about how the commands will execute (which files, what methods, what hyperparameters, etc.)
are determined by the ExperimentConfig.
The following diagram shows a hierarchy of the high level components that comprise an experiment configuration:
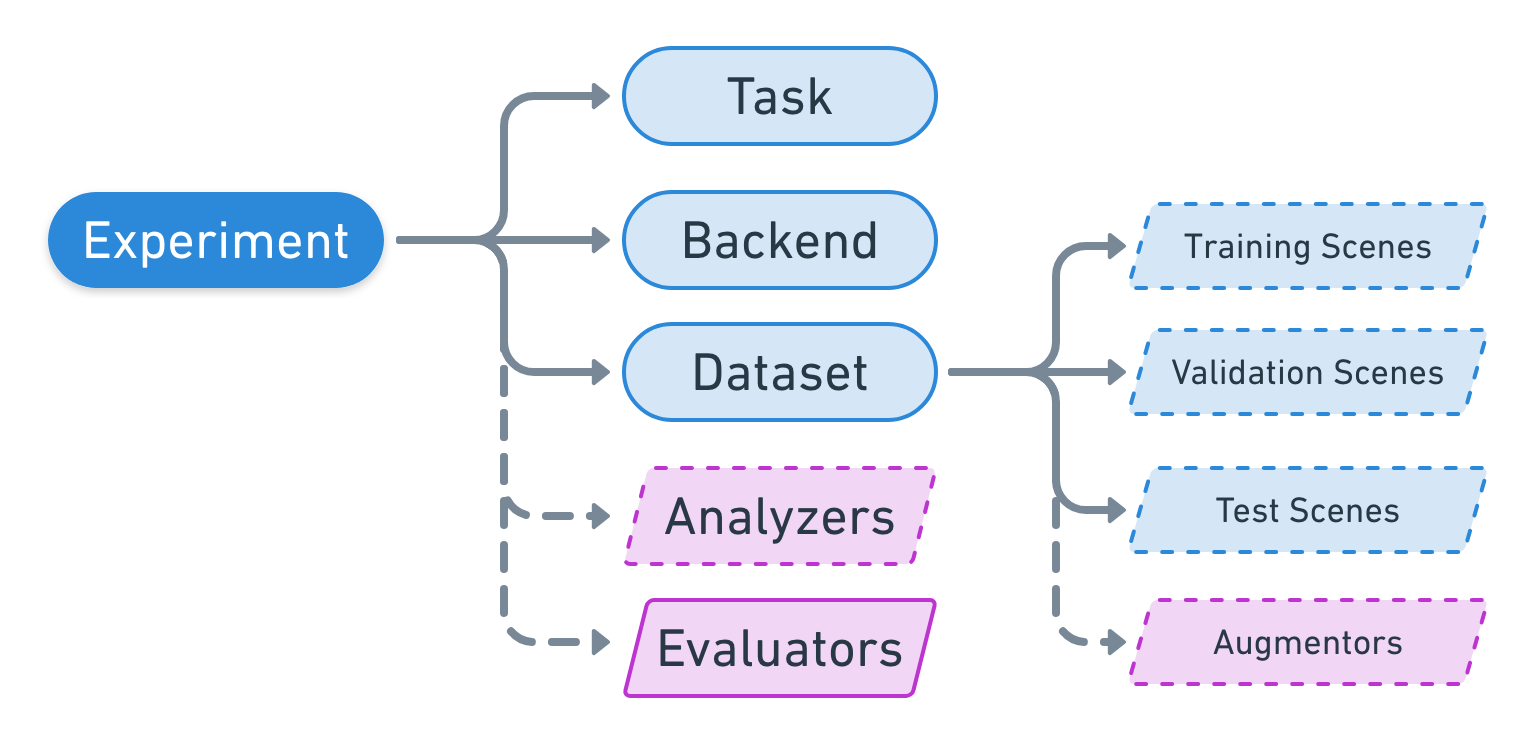
In the tiny_spacenet.py example, we can see that the experiment is the very last thing constructed
and returned.
experiment = rv.ExperimentConfig.builder() \
.with_id('tiny-spacenet-experiment') \
.with_root_uri('/opt/data/rv') \
.with_task(task) \
.with_backend(backend) \
.with_dataset(dataset) \
.with_stats_analyzer() \
.build()
Task¶
A Task is a computer vision task such as chip classification, object detection, or semantic segmentation.
Tasks are configured using a TaskConfig, which is then set into the experiment with the .with_task(task)
method.

Chip Classification¶
rv.CHIP_CLASSIFICATION
In chip classification, the goal is to divide the scene up into a grid of cells and classify each cell. This task is good for getting a rough idea of where certain objects are located, or where indiscrete “stuff” (such as grass) is located. It requires relatively low labeling effort, but also produces spatially coarse predictions. In our experience, this task trains the fastest, and is easiest to configure to get “decent” results.
Object Detection¶
rv.OBJECT_DETECTION
In object detection, the goal is to predict a bounding box and a class around each object of interest. This task requires higher labeling effort than chip classification, but has the ability to localize and individuate objects. Object detection models require more time to train and also struggle with objects that are very close together. In theory, it is straightforward to use object detection for counting objects.
Semantic Segmentation¶
rv.SEMANTIC_SEGMENTATION
In semantic segmentation, the goal is to predict the class of each pixel in a scene. This task requires the highest labeling effort, but also provides the most spatially precise predictions. Like object detection, these models take longer to train than chip classification models.
Future Tasks¶
It is possible to add support for new tasks by extending the Task class. Some potential tasks to add are chip regression (goal: predict a number for each chip) and instance segmentation (goal: predict a segmentation mask for each individual object).
TaskConfig¶
A TaskConfig is always constructed through a builder, which is created with key from the .build static method of TaskConfig. In our tiny_spacenet.py example, we configured an object detection task:
task = rv.TaskConfig.builder(rv.OBJECT_DETECTION) \
.with_chip_size(512) \
.with_classes({
'building': (1, 'red')
}) \
.with_chip_options(neg_ratio=1.0,
ioa_thresh=0.8) \
.with_predict_options(merge_thresh=0.1,
score_thresh=0.5) \
.build()
See also
The TaskConfigBuilder API Reference docs have more information about the Task types available.
Backend¶
To avoid reinventing the wheel, Raster Vision relies on third-party libraries to implement core functionality around building and training models for the various computer vision tasks it supports. To maintain flexibility and avoid being tied to any one library, Raster Vision tasks interact with third-party libraries via a “backend” interface inspired by Keras. Each backend is a subclass of Backend and contains methods for translating between Raster Vision data structures and calls to a third-party library.
Keras Classification¶
rv.KERAS_CLASSIFICATION
For chip classification, the default backend is Keras Classification, which is a small, simple library for image classification using Keras. Currently, it only has support for ResNet50.
TensorFlow Object Detection¶
rv.TF_OBJECT_DETECTION
For object detection, the default backend is the Tensorflow Object Detection API. It supports a variety of object detection architectures such as SSD, Faster-RCNN, and RetinaNet with Mobilenet, ResNet, and Inception as base models.
TensorFlow DeepLab¶
rv.TF_DEEPLAB
For semantic segmentation, the default backend is Tensorflow Deeplab. It has support for the Deeplab segmentation architecture with Mobilenet and Inception as base models.
Note
For each backend included with Raster Vision there is a list of Model Defaults with a default configuration for each model architecture. Each default can be considered a good starting point for configuring that model.
BackendConfig¶
A BackendConfig is always constructed through a builder, which is created with key from the .build static method of BackendConfig. In our tiny_spacenet.py example, we configured the TensorFlow Object Detection backend:
backend = rv.BackendConfig.builder(rv.TF_OBJECT_DETECTION) \
.with_task(task) \
.with_debug(True) \
.with_batch_size(8) \
.with_num_steps(5) \
.with_model_defaults(rv.SSD_MOBILENET_V2_COCO) \
.build()
See also
The BackendConfig API Reference docs have more information about the Backend types available.
Dataset¶
A Dataset contains the training, validation, and test splits needed to train and evaluate a model. Each dataset split is a list of scenes. A dataset can also hold Augmentors, which describe how to augment the training scenes (but not the validation and test scenes).
In our tiny_spacenet.py example, we configured the dataset with single scenes, though more often
in real use cases you call with_train_scenes and with_validaiton_scenes with many scenes:
dataset = rv.DatasetConfig.builder() \
.with_train_scene(train_scene) \
.with_validation_scene(val_scene) \
.build()
Scene¶

A scene represents an image, associated labels, and an optional Area of Interest (AOI) that describes what area of the scene has been exhaustively labeled. Labels are task-specific annotations, and can represent geometries (bounding boxes for object detection or chip classification), rasters (semantic segmentaiton), or even numerical values (for regression tasks, not yet implemented). Specifying an AOI allows Raster Vision to understand not only where it can pull “positive” chips from, or subsets of imagery that contain the target class we are trying to identify, but also lets Raster Vision know where it is able to pull “negative” examples, or subsets of imagery that contain none of the elements that are desired to be detected.
A scene is composed of the following elements:
Image: Represented in Raster Vision by a
RasterSource, an large scene image can contain multiple sub-images or a single file.Labels: Represented in Raster Vision as a
LabelSource, this is what provides the annotates or labels for the scene. The nature of the labels that are produced by the LabelSource are specific to the Task that the machine learning model is performing.AOI (Optional): An Area of Interest that describes which sections of the scene image (RasterSource) are exhaustively labeled.
In addition to the outline above, which describes training data completely, a LabelStore is also associated with scenes on which Raster Vision will perform prediction. The label store determines how to store and retrieve the predictions from a scene.
SceneConfig¶
A SceneConfig consists of a RasterSource optionally combined with a LabelSource, LabelStore, and AOI.
In our tiny_spacenet.py example, we configured the train scene with a GeoTIFF URI and a GeoJSON URI.
We pass in a built RasterSource, however we pass in just the URI for the LabelSource. This is because
the SceneConfig can construct a default LabelSource based on the URI using Default Providers.
train_scene = rv.SceneConfig.builder() \
.with_task(task) \
.with_id('train_scene') \
.with_raster_source(train_raster_source) \
.with_label_source(train_label_uri) \
.build()
The validation scene is also constructed very similary. However, it’s worth noting that the
LabelStore is not even mentioned in the building of the configuraiton. This is because
the prediction label store can be deteremined by Default Providers, by finding the
default LabelStore provider for a given task.
RasterSource¶
A RasterSource represents a source of raster data for a scene, and has subclasses for various data sources. They are used to retrieve small windows of raster data from larger scenes. You can also set a subset of channels (i.e. bands) that you want to use and their order using a RasterSource. For example, satellite imagery often contains more than three channels, but pretrained models trained on datasets like Imagenet only support three (RGB) input channels. In order to cope with this situation, we can select three of the channels to utilize.
GeoTIFF¶
rv.GEOTIFF_SOURCE
Georeferenced imagery stored as GeoTIFFs can be read using a GeoTIFFSource. If there are multiple image files that cover a single scene, you can pass the corresponding list of URIs using with_uris(), and read from the RasterSource as if it were a single stitched-together image. This is implemented behind the scenes using Rasterio, which builds a VRT out of the constituent images.
Image¶
rv.IMAGE_SOURCE
Non-georeferenced images including .tif, .png, and .jpg files can be read using an ImageSource. This is useful for oblique drone imagery, biomedical imagery, and any other (potentially massive!) non-georeferenced images.
Segmentation GeoJSON¶
rv.GEOJSON_SOURCE
Semantic segmentation labels stored as polygons and lines in a GeoJSON file can be rasterized and read using a GeoJSONSource. This is a slightly unusual use of a RasterSource as we’re using it to read labels, and not images to use as input to a model.
RasterSourceConfig¶
In the tiny_spacenet.py example, we build up the training scene raster source:
train_raster_source = rv.RasterSourceConfig.builder(rv.GEOTIFF_SOURCE) \
.with_uri(train_image_uri) \
.with_stats_transformer() \
.build()
See also
The RasterSourceConfig API Reference docs have more information about the RasterSource types available.
LabelSource¶
A LabelSource is an object that allows reading ground truth labels for a scene. There are subclasses for different tasks and data formats. They can be queried for the labels that lie within a window and are used for creating training chips, as well as providing ground truth labels for evaluation against validation scenes.
In the tiny_spacenet.py example, we build up the training scene raster source:
train_raster_source = rv.RasterSourceConfig.builder(rv.GEOTIFF_SOURCE) \
.with_uri(train_image_uri) \
.with_stats_transformer() \
.build()
See also
The LabelSourceConfig API Reference docs have more information about the LabelSource types available.
LabelStore¶
A LabelStore is an object that allows reading and writing predicted labels for a scene. There are subclasses for different tasks and data formats. They are used for saving predictions and then loading them during evaluation.
In the tiny_spacenet.py example, there is no explicit LabelStore supplied on the validation scene. It instead relies on the Default Providers architecture to determine the correct label store to use. If we wanted to state the label store explicitly, the following code would be equivalent:
val_label_store = rv.LabelStoreConfing.builder(rv.OBJECT_DETECTION_GEOJSON) \
.build()
val_scene = rv.SceneConfig.builder() \
.with_task(task) \
.with_id('val_scene') \
.with_raster_source(val_raster_source) \
.with_label_source(val_label_uri) \
.with_label_store(val_label_store) \
.build()
Notice the above example does not set the explicit URI for where the LabelStore will store it’s labels.
We could do that, but if we leave that out the Raster Vision logic will set that path explicitly
based on the exeriment’s root directory and the predict command’s key.
See also
The LabelStoreConfig API Reference docs have more information about the LabelStore types available.
Raster Transformers¶
A RasterTransformer is a mechanism for transforming raw raster data into a form that is more suitable for being fed into a model.
See also
The RasterTransformerConfig API Reference docs have more information about the RasterTransformer types available.
Augmentors¶
Data augmentation is a technique used to increase the effective size of a training dataset. It consists of transforming the images (and labels) using random shifts in position, rotation, zoom level, and color distribution. Each backend has its own ways of doing data augmentation inherited from its underlying third-party library, but some additional forms of data augmentation are implemented within Raster Vision as Augmentors.
For instance, there is a NodataAugmentor which adds blocks of NODATA values to images to learn to avoid making spurious predictions over NODATA regions.
See also
The AugmentorConfig API Reference docs have more information about the Augmentors available.
Analyzers¶
Analyzers are used to gather dataset-level statistics and metrics for use in downstream processes. Currently
the only analyzer available is the StatsAnalyzer, which determines the distribution of values over
the imagery in order to normalize values to uint8 values in a StatsTransformer.
See also
The AnalyzerConfig API Reference docs have more information about the Analyzers available.
Evaluators¶
For each task, there is an evaluator that computes metrics for a trained model. It does this by measuring the discrepancy between ground truth and predicted labels for a set of validation scenes.
Normally you will not have to set any evaluators into the ExperimentConfig, as the default
architecture will choose the evaluator that applies to the specific Task the experiment pertains to.
See also
The EvaluatorConfig API Reference docs have more information about the Evaluators available.
Default Providers¶
Default Providers allow Raster Vision users to either state configuration simply, i.e. give a URI instead of a full configuration, or not at all. Defaults are provided for a number of configurations. There is also the ability to add new defaults via the Plugins architecture.
For instance, you can specify a RasterSource and LabelSource just by a URI, and the Defaults registered with the Global Registry will find a default that pertains to that URI. There are default LabelStores and Evaluators per Task, so you won’t have to state them explicitly unless you need additional configuration or are using a non-default type.