Basic Concepts#
At a high-level, a typical machine learning workflow for geospatial data involves the following steps:
Read geospatial data
Train a model
Make predictions
Write predictions (as geospatial data)
Below, we describe various Raster Vision components that can be used to perform these steps.
Reading geospatial data#
Raster Vision internally uses the following pipeline for reading geo-referenced data and coaxing it into a form suitable for training computer vision models.
When using Raster Vision as a library, users generally do not need to deal with all the individual components to arrive at a working GeoDataset (see the tutorial on Sampling training data), but certainly can if needed.

Below, we briefly describe each of the components shown in the diagram above.
RasterSource#
Tutorial: Reading raster data
A RasterSource represents a source of raster data for a scene. It is used to retrieve small windows of raster data (or chips) from larger scenes. It can also be used to subset image channels (i.e. bands) as well as do more complex transformations using RasterTransformers. You can even combine bands from multiple sources using a MultiRasterSource or stack images from sources in a time-series using a TemporalMultiRasterSource.
VectorSource#
Tutorial: Reading vector data
Annotations for geospatial data are often represented as vector data such as polygons and lines. A VectorSource is Raster Vision’s abstraction for a vector data reader. Just like RasterSources, VectorSources also allow transforming the data using VectorTransformers.
LabelSource#
Tutorial: Reading labels
A LabelSource interprets the data read by raster or vector sources into a form suitable for machine learning. They can be queried for the labels that lie within a window and are used for creating training chips, as well as providing ground truth labels for evaluation against model predictions. There are different implementations available for chip classification, semantic segmentation, and object detection.
Scene#
Tutorial: Scenes and AOIs
A Scene is essentially a combination of a RasterSource and a LabelSource along with an optional AOI which can be specified as one or more polygons.
It can also
hold a LabelStore; this is useful for evaluating predictions against ground truth labels
just have a RasterSource without a LabelSource or LabelStore; this can be useful if you want to turn it into a dataset to be used for unsupervised or self-supervised learning
Scenes can also be more conveniently initialized using the factory functions defined in rastervision.core.data.utils.factory.
GeoDataset#
Tutorial: Sampling training data
A GeoDataset (provided by Raster Vision’s pytorch_learner plugin) is a PyTorch-compatible dataset that can readily be wrapped into a DataLoader and used by any PyTorch training code. Raster Vision provides a Learner class for training models, but you can also use GeoDatasets with either your own custom training code, or with a 3rd party library like PyTorch Lightning.
See also
AlbumentationsDataset(base dataset class)-
Training a model#
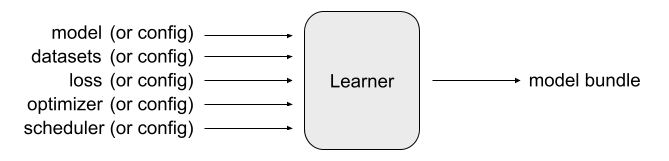
Learner#
Tutorial: Training a model
Raster Vision’s pytorch_learner plugin provides a Learner class that encapsulates the entire training process. It is highly configurable. You can either fill out a LearnerConfig and have the Learner set everything up (datasets, model, loss, optimizers, etc.) for you, or you can pass in your own models, datasets, etc. and have the Learner use them instead.
The main output of the Learner is a trained model. This is available as a last-model.pth file which is a serialized dictionary of model weights that can be loaded into a model via
model.load_state_dict(torch.load('last-model.pth'))
You can also make the Learner output a “model-bundle” (via save_model_bundle()), which outputs a zip file containing the model weights as well as a config file that can be used to re-create the Learner via from_model_bundle().
There are Learner subclasses for chip classification, semantic segmentation, object detection, and regression.
Note
The Learners are not limited to GeoDatasets and can work with any PyTorch-compatible image dataset. In fact, pytorch_learner also provides an ImageDataset class for dealing with non-geospatial datasets.
See also
Making predictions and saving them#
Tutorial: Prediction and Evaluation

Having trained a model, you would naturally want to use it to make predictions on new scenes. The usual workflow for this is:
Instantiate a
Learnerform a model-bundle (viafrom_model_bundle())Instantiate the appropriate
SlidingWindowGeoDatasetsubclass e.g.SemanticSegmentationSlidingWindowGeoDataset(can be done easily using the convenience methodfrom_uris())Pass the
SlidingWindowGeoDatasettoLearner.predict_dataset()Convert predictions into the appropriate Labels subclass e.g.
SemanticSegmentationLabels(viafrom_predictions())Save the Labels to file (via
save())Alternatively, you can Instantiate an appropriate LabelStore subclass and pass the
LabelstoLabelStore.save()
Labels#
The Labels class is an in-memory representation of labels. It can represent both ground truth labels and model predictions.
LabelStore#
A LabelStore abstracts away the writing of Labels to file. It can also be used to read previously written predictions back as Labels which is useful for evaluating predictions.